


The Rise of zkEVM Rollups
Exploring the frontiers of Ethereum scaling, this article dives into what a zkEVM is, why it matters & what technological approaches the leading protocols are taking

Why should you read this?
Zero knowledge rollups are the future of Ethereum scaling & the rise of EVM-compatible zk-rollups (zkEVM) is a big step towards unlocking unprecedented scalability for entire ecosystems of composable applications on Ethereum’s layer 2.
This article will get you up to speed.
But before we dive into zkSync, Scroll, Polygon zkEVM & StarkWare’s Starknet (the leading zkEVM protocols), let’s first have a look what the Ethereum Virtual Machine (EVM) is:
So basically, the EVM is a piece of software that executes smart contracts & computes the state of the Ethereum network after a new block is added to the chain. The EVM sits on top of Ethereum’s hardware & node layer & its main purpose is computing the network's state & compiling various types of smart contract code (written in human-readable programming languages) into a machine-readable format called bytecode to run the smart contracts. The EVM hence powers smart contract execution and is one of the core features of Ethereum. Instead of a classic distributed ledger of transactions, the EVM transforms Ethereum into a distributed state machine.
Ethereum's state is a large data structure which holds not only all accounts & balances, but also an overall network or machine state which can change from block to block according to a pre-defined set of rules. At any given block in the chain, Ethereum has one & only one canonical state with the rules for valid state transition, being defined by the EVM.
But now that we have a basic understanding of what the EVM is, WTF is a zkEVM?
A zkEVM is a virtual machine that executes smart contracts in a way that is compatible with zero-knowledge-proof computation and the programming languages supported by the originial EVM. However, this can be quite difficult to build. A zkEVM rollup's main goal is to run EVM bytecode. Unfortunately though, zk-proofs require all the computational statements they are proving to be converted into a very specific format to then be compiled down into a STARK/SNARK, which makes it hard to implement in an EVM context .
However, there are a few ways to do this:
- Prove the EVM execution trace directly by converting it into the verifiable format (Scroll)
- Create a custom VM, map EVM opcodes to opcodes for that VM & prove correctness of the trace in that custom environment (Polygon zkEVM)
- Create a custom VM, transpile Solidity into the custom VM’s bytecode (directly, or via a custom high level language) & prove in a custom environment (zkSync & StarkWare)
But before we have a closer look at how the individual protocols do it, lets have a look at why zkEVMs matter?!
Well, primarily because zkEVMs for the first time enable general purpose zk-rollups. So far, we have only seen application-specific zk-rollups & validiums. zkEVM will now finally unlock zk-rollups's unprecedented scalability for entire ecosystems of composable DeFi protocols & potentially even (application-specific) recursive rollup structures on top of zkEVMs (L3 scaling as outlined by StarkWare, see Twitter thread linked below).


But what are zk-rollups you ask?
High-level, zk-rollups use fancy cryptography to take some of the load off Ethereum’s L1, resulting in increased throughput & lower tx fees on L2 for more info see:

zkRollups rely on validity proofs in the form of zero knowledge proofs (e.g. SNARKs or STARKs). A relayer collects transaction data on L2 and is responsible for generating the zk proof. While app-specific rollups (dYdX, ImmutableX, Loopring) have already gained traction in the past, the technology needs general purpose rollups in order to onboard developers & users to generate network effects as quickly as possible. Rollup teams are hence deeply concerned about - migrating existing Ethereum contracts (& devs) to their rollup - being supported by existing EVM tooling (e.g. libraries, wallets, marketplaces etc.).
The simplest way to achieve both goals is to create a zkEVM as outlined above.
But let's get into the zkEVM wars!
Back in July, a trio of announcements from Scroll, zkSync & Polygon kicked off the race to mainnet, a.k.a. the zkEVM wars, as each company implied that it would be the “first” to bring a zkEVM to market.
As recently described by Scroll founder @LuozhuZhang in a Twitter thread, there are basically three different types of zkEVMs:
- bytecode level
- language level
- consensus level
Based on this definitions all above zkEMVs fall in the first two categories.

The holy grail of zkEVMs basically is reaching full bytecode-level compatibility and hence what is referred to as EVM equivalence (a term coined by the team behind the optimistic rollup “Optimism”):

But let’s start with zkSync’s EVM implementation.
For more info on zkSync in general, see:

In terms of type of zkEVM, zkSync 2.0 falls into the language-level bucket. Consequently, devs can write smart contracts in Solidity, but zkSync transpiles that code into a language optimized for zk-proofs called Yul behind the scenes.

While Matter Labs (company behind zkSync), claims that this system was engineered to provide the rollup scalability advantages, primarily in the proofing process, by most definitions, zkSync’s EVM implementation would likely be described as EVM-compatible rather than EVM-equivalent. Not being equivalent means that zkSync potentially isn’t 1:1 compatible with every single Ethereum tool out there, which might result in additional overhead for devs. However, Matter Labs insists that this shouldn’t be an issue in the long-term. This is similar to the approach StarkWare takes with StarkNet & the programming language Cairo.
Starknet is based on the Cairo programming language, which is optimized for zk-proofs. To enable smart contracts & composability, StarkNet takes a language-level compatibility approach & transpiles EVM-friendly languages (e.g. Solidity) down to a STARK-friendly VM (in Cairo).
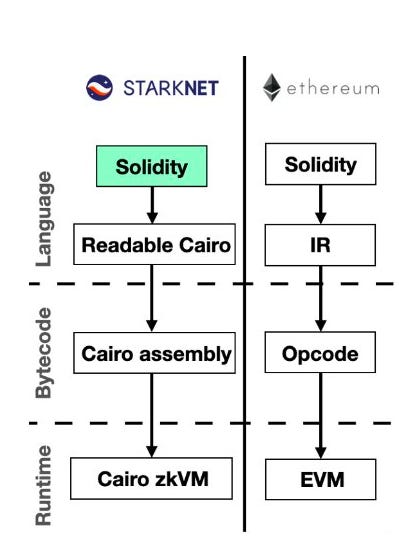
Just two days ago, StarkWare announced Cairo 1.0 which it claims will enhance usability, safety & convenience:


Scroll & Polygon on the other hand, are both taking the maybe a bit more ambitious bytecode-level approach to their zkEVMs. These approaches rip out the transpiler step completely, meaning they don’t convert Solidity code into a separate language before it gets compiled & interpreted. This generally results in better compatibility with the EVM. But even here, there are distinctions that probably make Scroll more of a “true” zkEVM than Polygon’s implementation. When Polygon announced bringing the first EVM-equivalent zkEVM to market back in July, it was quickly pointed out by many that the zkEVM implementation likely better described as EVM-compatible rather than EVM-equivalent based on its specifications.
As outlined in an article by Messari (a leading crypto research company) last month, part of the “true EVM” debate follows whether the EVM bytecode is being executed directly or interpreted first & then executed. In other words, if a solution does not mirror official EVM specs, it cannot be considered a "true zkEVM". Based on this definition, Scroll might be considered a "true zkEVM" vs. the others introduced here as it aims to execute EVM bytecode directly.
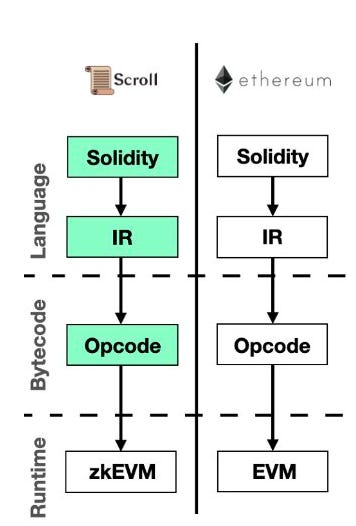
According to Messari, Polygon on the other hand uses a new set of assembly codes to express each opcode, the human-readable translation of bytecode, which could theoretically allow the behavior of the code to be different on the EVM.

Hence, overall Polygon might be a bit further from EVM equivalence than its main bytecode competitor Scroll.

Anyhow, time will tell what approach will find the most adoption but I'm definitely hyped for the zkEVM wars and the scaling zkEVMs unlock across the Ethereum ecosystem. The first zkEVM mainnets are quickly approaching with zkSync in the lead, where mainnet is only 44 days away now:

Polygon & Scroll both aim to launch mainnet in Q1 2023, while Starknet's mainnet is likely also not far away!