
Scaling Ethereum on Rollups
A look into the future of the Ethereum network

With Ethereum’s transition to Proof of Stake, a.k.a. the merge ahead & EIP-4844 coming up, it's time to deep dive into the scalability problem, how rollups work, why they matter & how they will shape the future of the Ethereum ecosystem as powerful execution layers that use the Ethereum L1 as a settlement layer for batches of thousands transactions.
So first of all, let’s have a look at how approaches to the scalability problem have evolved over time:
Increasing the scalability of blockchains has long been a main topic in the crypto space. Originally, the key idea behind decentralized, permissionless & trustless networks was to have a culture of users verifying the chain, as for example is the case with Ethereum. In order to scale throughput, some alternative L1 blockchains have decided to go with a more centralized network where users have to trust a smaller number of validators with high-spec machines, sacrificing decentralization & security for scalability. This trade-off resembles the blockchain trilemma, which addresses the challenges developers face in creating a blockchain that is scalable, decentralized and secure, without compromising on any aspect (see figure 1 below).

Another popular scaling technique is to break the network into multiple chains (shard chains), with communication protocols between them as illustrated in figure 2 below.

This provides high scalability, as the computational load can be spread across multiple chains. It also maintains a higher degree of decentralization as each of these chains will still be accessible for verification or usage by the average user (as the hardware requirements don’t increase if throughput per chain is not increased). However, sharded networks tend to make significant compromises on security, as the validator set is being split up into subnets between multiple chains. While more naive variants of sharding have different validator sets for the different chains, more sophisticated implementations have dynamic validator subsets. But regardless, the split validator set is less secure by definition.
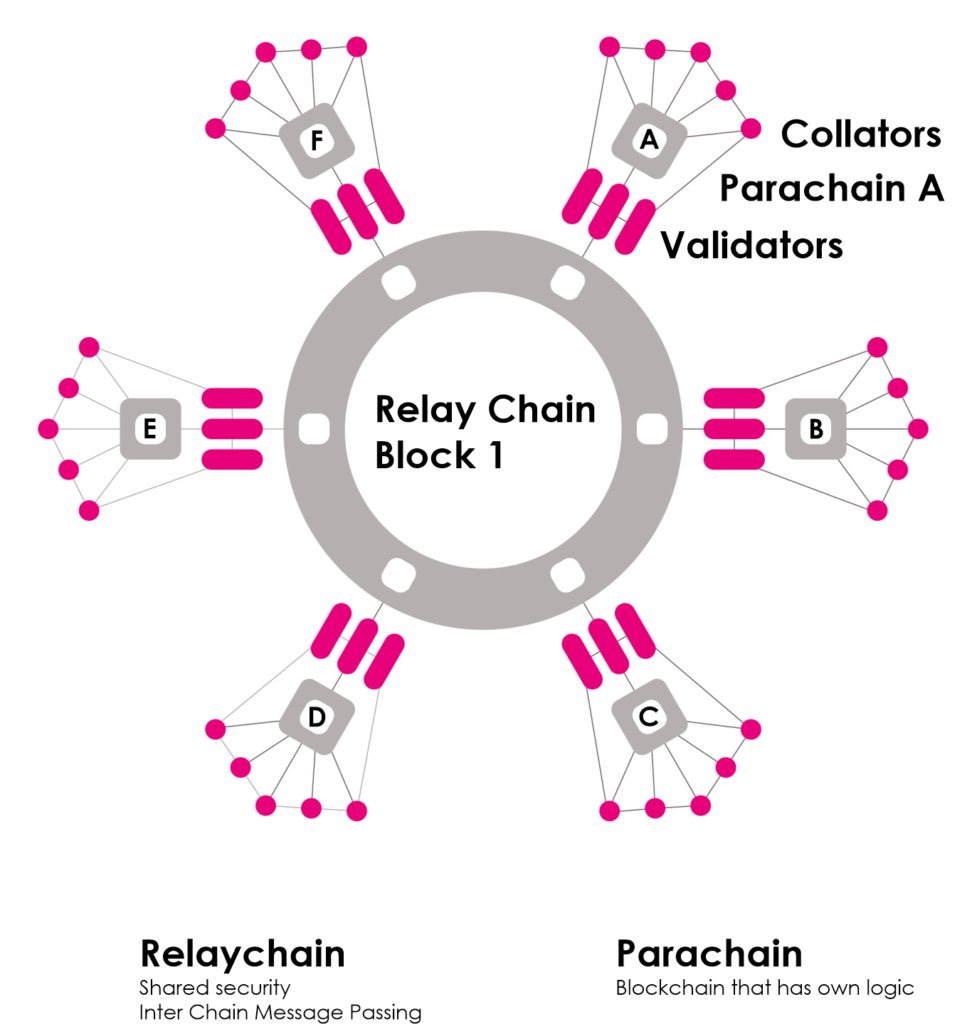
The next idea was to take the multiple chains approach, but enable shared security across all chains by posting fraud proofs from each shard chain to a central security chain. Polkadot started with this model. Polkadot’s shards (a.k.a. parachains) are application-specific and parachain operators can customize each chain to its use case within the specifications of the overall network (see figure 3).
But what are rollups?!
Well, rollups take this to the next level. Rollups are a scaling solution in which transactions are processed off-chain (on L2) and rolled up into batches. Sequencers/relayers collect transaction data on the L2 and submit the data to a smart contract on Ethereum L1 that enforces correct transaction execution on L2 and stores the transaction data on L1, inheriting the battle-tested security of the Ethereum base layer. So now what were essentially shards or parachains are completely decoupled from the network and devs have a wide open space to develop their L2 “chain” however they want. Meanwhile, devs are still able to leverage on Ethereum L1’s security by communicating through arbitrary smart contracts developed in a way that is optimized for the specific rollup. Also, a rollup does not need a validator set of its own. A rollup system only needs to have a set of sequencers, with only one sequencer needing to be live at any given time.
With optimistic rollups for example, at least one honest full node is needed to report fraud, so there’s some pressure to keep a full node accessible. However, with weak assumptions like this, rollups can actually run on a small set of high-spec server-grade machines, allowing for great scalability. Instead of consensus mechanisms, rollups can also have coordination mechanisms with rotation schedules to rotate sequencers accordingly, thereby increasing security & reducing the time the high-spec machines need to be online.
For more info see: https://polynya.medium.com/brainstorming-sequencer-consensus-mechanisms-d7304bae4765
Generally, there are two types of rollup systems. The before-mentioned optimistic rollups are characterized by having a sequencer node that collects transaction data on L2 and submits this data alongside the new L2 state root to ETH L1.

In order to ensure that the new state root which is submitted to ETH L1 is correct, verifier nodes will compare their new state root to the one submitted by the sequencer. If they notice a difference, they will begin what’s called a fraud proof. If the fraud proof’s state root is different from the one submitted by the sequencer, the sequencer’s initial deposit (a.k.a. bond) will be slashed. The state roots from that transaction onward will be erased and the sequencer will have to recompute the lost state roots.
zkRollups on the other hand rely on validity proofs in the form of zero knowledge proofs (e.g. SNARKs or STARKs). A relayer collects transaction data on L2 and is responsible for generating the zk proof for the transaction batch. The zk proof the relayer computes reports only the changes in L2 state and provides this data to the L1 smart contract in the form of a verifiable hash. Similar to sequencers in optimistic rollups, relayers have to stake a bond in the smart contract on L1 in order to incentivize honest behaviour.

But why do rollups matter?!
Rollups play an especially important role in Ethereum 2.0’s rollup-centric roadmap. Along with proof of stake, the central feature in ETH 2.0’s design is sharding. ETH 2.0 introduces a limited form of sharding called “data sharding”. As per Ethereum's rollup-centric roadmap, the shards would store data & attest to the availability of ~250 kB sized blobs of data (see figure 6). This availability verification provides a secure and high-throughput settlement & data availability layer for L2 protocols such as rollups. However, the shards do not execute any transactions themselves.
For more info see: https://hackmd.io/@vbuterin/sharding_proposal

Through Ethereum 2.0’s data sharding, Ethereum aims to address the data availability problem, which refers to the question how peers in a blockchain network can be sure that all the data of a newly proposed block is actually available to the network. If the data is not available, the block might contain malicious transactions which are being hidden by the block producer. Even if the block contains non-malicious transactions, hiding them might compromise the security of the system. This data availability problem is especially prominent in the context of rollup systems. It is very important that sequencers can make transaction data available, as the rollup needs to know about the state and account balances. This also introduces limitations to rollups
Because even if the sequencer were an actual supercomputer, the number of transactions per second it can actually compute will be limited by the data throughput of the underlying data availability solution/layer it uses. If the data availability solution/layer used by a rollup is unable to keep up with the amount of data the rollup’s sequencer wants to dump on it, then the sequencer (and hence the rollup) can’t process more transactions even if it wanted to.
So how does Ethereum’s future look like?
By transforming the Ethereum L1 into a major data availability / settlement layer for rollups, the Ethereum network and its rollup ecosystems will scale almost infinitely. Already today, advanced optimistic rollups like Arbitrum, application-specific volitions like ImmutableX or optimistic rollups relying on alternative data availability solutions like Metis (using an off-chain DA solution similar to a volition) can reach hundreds and thousands of transactions per second. With EIP-4844 coming up (see next post), transaction fees on rollups will fall to fractions of cents and will unlock even greater scalability. This effect will be multiplied, once full data sharding (a.k.a. danksharding) is implemented, greatly improving data availability on Ethereum.
Finally, other upcoming L1 protocols like Celestia, a modular consensus and data availability base layer for rollup L2s or Polygon Avail (basically the same), also aim to unlock the potential of rollup scaling by providing a pluggable and highly optimized data availability solution to rollup execution layers.
Thanks to their shared security approaches, Polkadot parachains and Ethereum rollups remove the bottleneck of having to source an independent validator set and thereby make it easier to deploy chains. Additionally, maturing developer tools like Polkadot’s Substrate framework, have significantly reduced complexity for developers. However, Polkadot’s shared security model is expensive and its costly to deploy parachains (cost of winning a parachain slot), while rollups on Ethereum remain expensive to operate (at least pre EIP-4844 and data sharding). Modular data availability layers like Celestia appear to be the next evolution of the trend to make deploying new chains as easy (and cheap) as possible. Celestia’s modular architecture makes integration easy for both rollups as well as application-specific L1s (execution layers) that can profit from maximum data availability at minimal cost. Various implementations that leverage on Celestia’s data availability are visualized in figure 7. Modular scaling, shared security & rollups are likely to not only shape the future of the Ethereum network, but rather the entire crypto space.

I hope you liked this article. If you did, please support us by subscribing on Substack and following on Twitter or sharing the article with your friends & colleagues. We will publish more content on advanced topics around rollup scaling, Ethereum 2.0, zk tech and project deep-dives, so stay tuned!